@misc{gao2025vlmgineer,
title={VLMgineer: Vision Language Models as Robotic Toolsmiths},
author={George Jiayuan Gao and Tianyu Li and Junyao Shi and Yihan Li and Zizhe Zhang and Nadia Figueroa and Dinesh Jayaraman},
year={2025},
eprint={2507.12644},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2507.12644},
}RoboToolBench
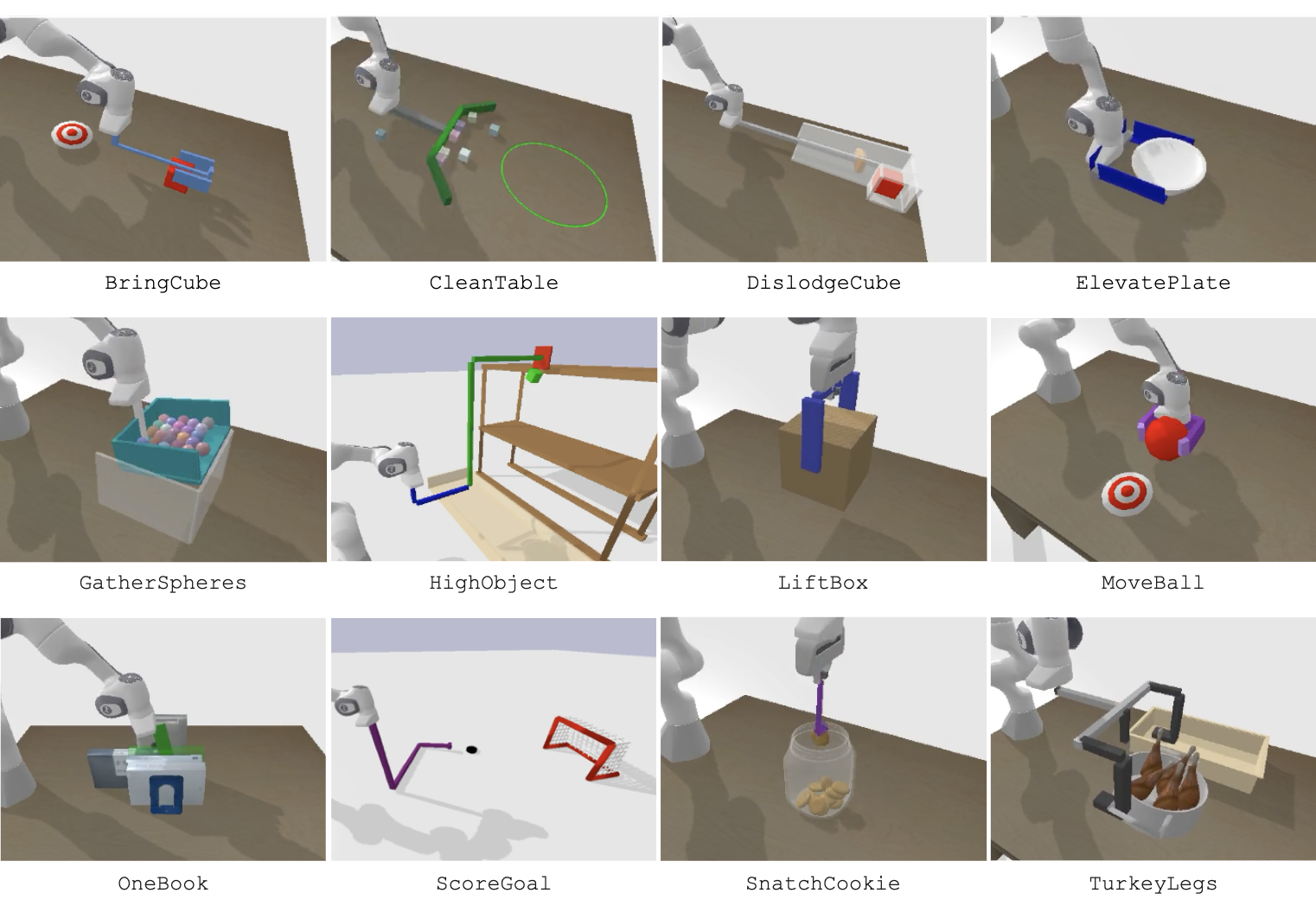
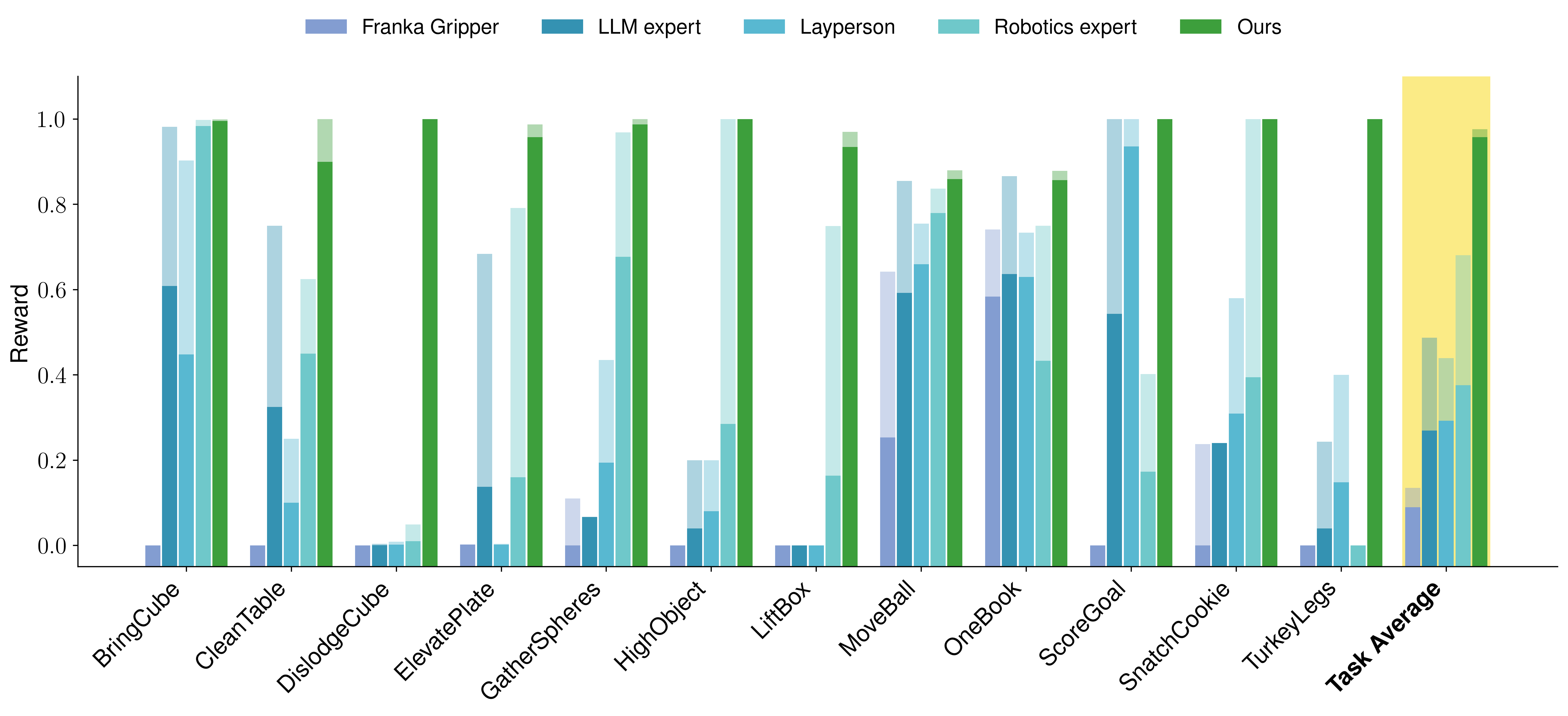
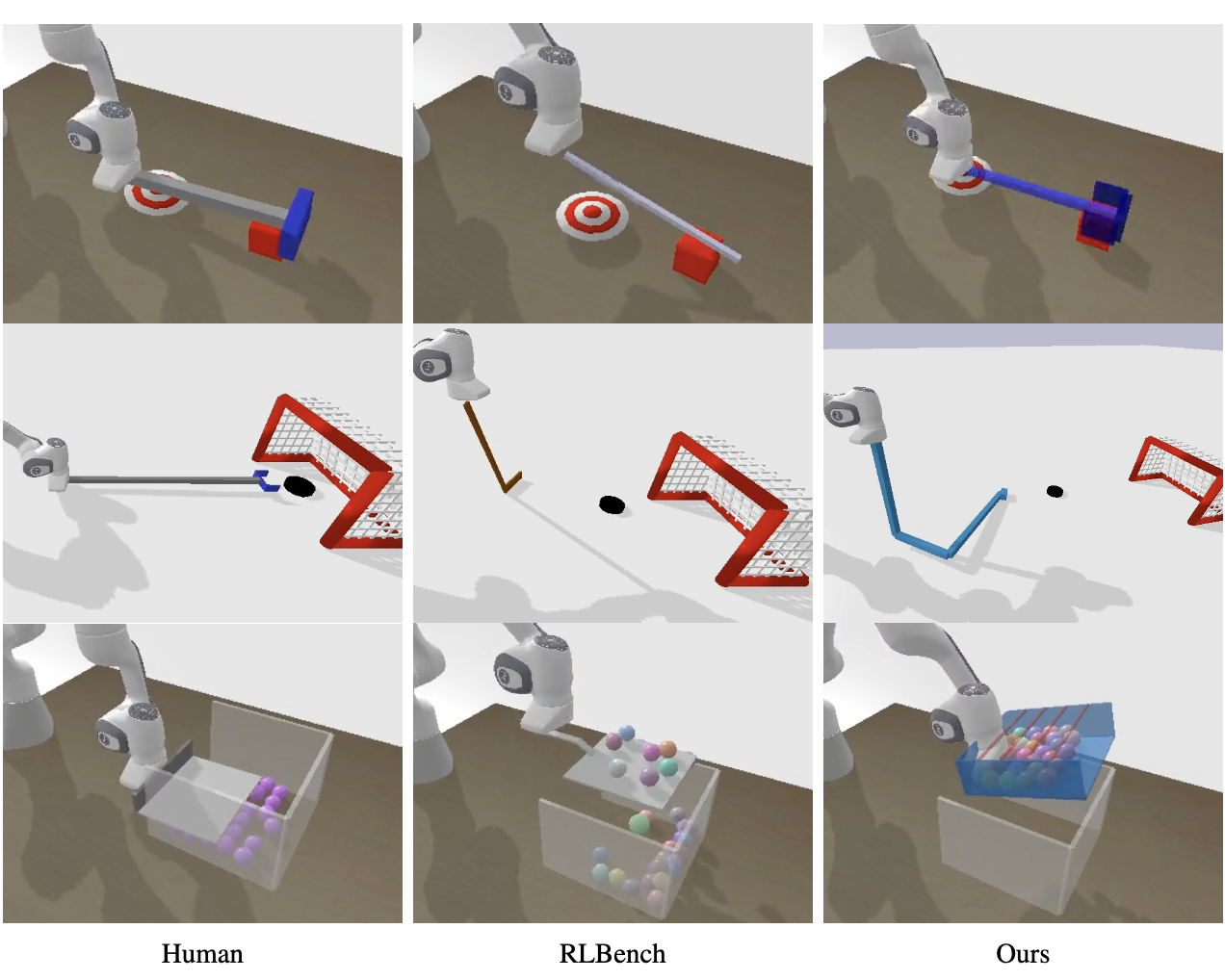
VLMgineer produces innovative tool designs and their corresponding actions across 12 diverse tasks in RoboToolBench that are challenging to perform using a general-purpose robot arm and gripper.